论文地址: DOI: 10.1109/MSR66628.2025.00043(MSR 2025 会议论文)。
这篇文章的核心在于挑战了大数据迷信,证明了在 Code Review 任务中,清洗掉噪声数据(即使丢掉一大半数据),模型效果反而更好。
核心发现:Less is More
现有的开源代码审查数据集(如 CodeReviewer)虽然很大,但充满了“噪声”。
- 什么是Noisy? 比如 “Why do we have this flag?”(单纯的提问)或者 “Looks good”(无实质内容)。
- 什么是Valid? 明确指出了问题并给出了修改建议的评论。
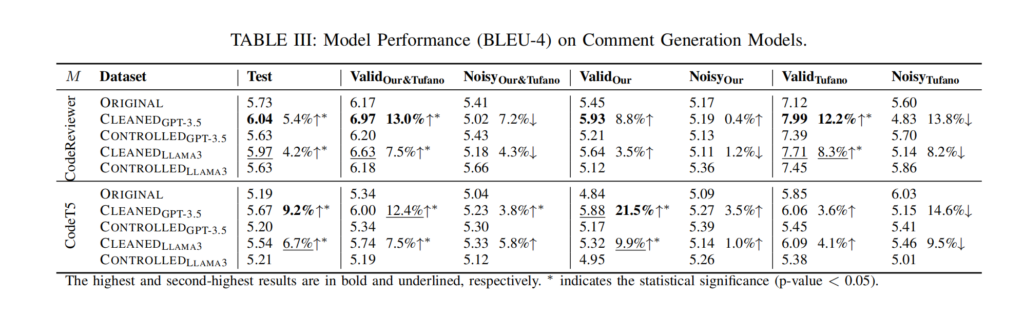
文章发现,直接用 LLM(如 GPT-3.5 或 Llama 3)清洗掉这些噪声后,虽然训练数据量减少了 25% – 66%,但训练出来的模型 BLEU 分数反而提升了 13% 左右。

实验设计的亮点:Controlled Baseline (受控基线)
这一部分非常值得我们在写论文时模仿。为了证明模型效果提升是因为“数据质量变好了”,而不是因为“数据量变少了”,作者设计了一个非常严谨的对照组。
- Original: 使用全部原始数据(含噪声)。
- Cleaned: 使用 LLM 清洗后的数据(纯净,但数据量小)。
- Controlled (关键!): 从原始数据中随机抽取与 Cleaned 组相同数量的数据。
结果: Controlled 组的效果比 Original 还差。这强有力地证明了:单纯减少数据量会掉点,只有剔除噪声(提升质量)才能涨点。
方法论:LLM-based Semantic Cleaning
作者没有训练复杂的分类器,而是直接利用 LLM 的 Prompt Engineering 来清洗数据。流程如下:
- Definition:明确定义 Valid 和 Noisy 的标准。
- Prompt Design:设计 System Prompt(角色设定+定义)和 User Prompt(代码 Diff + 评论)。
- Filtering:让 LLM 判断每条数据是 Valid 还是 Noisy,只保留 Valid。
文中测试了两种 Prompt 策略:仅包含定义(P_DEFINITION)和 包含辅助规则(P_AUXILIARY)。结果发现直接给定义效果就很好了。

结尾碎碎念
这篇文章的成本分析 Discussion 很有意思。作者算了一笔账:用 GPT-3.5 清洗整个数据集只花了 50 美元,耗时 39 小时;而如果找人标注(众包),预计要花费 25,600 美元。这简直是 LLM 降本增效的完美案例。
另外,这也提醒我们,做数据集的时候不要一味追求大。Garbage in, Garbage out,如果数据里全是“LGTM”或者“What is this”,模型再大也学不到东西。
0 条评论