论文地址:https://doi.org/10.1145/3728931
中英对照翻译:
RIE
之前研究 Code Review 更多关注“情感(Sentiment)”或“有用性(Usefulness)”,但这篇论文首次系统性地界定了什么是“清晰(Clarity)”。作者通过文献综述 + 工业界访谈 + 103份问卷调查,总结出了 RIE 三大属性。
这个分类非常细致,把标准分为了 Essential (必须项) 和 Optional (加分项),具体的:
- Relevance (相关性)
- [Essential] 自解释且相关:评论必须针对当前变更,且不需要跳转外部链接就能看懂。
- [Optional] 精确定位(Specify Location) & 体现理解(Show Understanding)。
- Informativeness (信息性) —— 作者说这是论文发现最容易缺失的属性
- [Essential] 意图清晰(Clear Intention):是提问、报错还是建议?
- [Essential] 提供理由(Reasoning):不能只说“不对”,要解释“为什么”。
- [Optional] 下一步建议(Next Step) & 参考资料(References)。
- Expression (表达)
- [Essential] 简洁切题(Concise)。
- [Essential] 礼貌客观(Polite & Objective):对事不对人。
- [Optional] 格式易读 & 语法正确。
研究的方法论
方法上,这篇论文的研究方法非常严谨awa,值得学习:
- 使用了 Open Card Sorting 来归纳 RIE 属性。
- 在人工标注阶段,使用了 Cohen’s Kappa 系数来衡量一致性,达到了 0.87,说明定义的 RIE 标准具有很高的可操作性和共识度。
- 针对9种编程语言,基于 95% 置信水平和 5% 置信区间进行随机采样,保证了样本的代表性。
补充:
Open Card Sorting:根据内容,归纳出主题,没有预设的分类标准,这是一种聚类的方法。
Cohen’s Kappa 系数:这是用来衡量两个人给同一个东西打分,意见一致程度的指标。
分析一下数据
通过对 2,438 条开源项目评论的人工检查,发现了一些可能反直觉的现状:
- 总体约 28.8% 的评论在清晰度上存在缺陷。Informativeness 是重灾区(19.3% 不合格)。大量 Reviewer 只是抛出问题(比如 “This is wrong”),却不提供上下文或理由,导致用户一头雾水。
- C 和 Java 项目表现最好(>75% 全合格); C++ 项目表现最差(只有 63.6% 全合格)。
ClearCRC:自动化评估框架
论文提出了 ClearCRC 框架来自动评估评论质量。对比了三组模型:(1) 传统 ML/DL (RF, LSTM); (2) 预训练模型 (CodeBERT, CodeReviewer); (3) LLMs (Llama3, CodeLlama)。
关键结论:
- 在这个特定任务上,CodeBERT 和 CodeReviewer 表现最好,甚至击败了参数量大得多的 LLMs。大模型(Zero-shot/Few-shot)虽然通用能力强,但在捕捉“清晰度”这种需要结合代码上下文的细粒度特征时,不如经过 Fine-tuning 的小模型。
- 另外, CodeBERT (125M) 以 CodeReviewer 一半的参数量达到了相当的效果,泛化能力很强。
- 由于负样本较少,训练时使用了 Up-sampling 策略,来提升 Balanced Accuracy 。
补充:
Up-sampling:ai解释为:一个用来解决“数据偏科”(也就是专业术语叫“类别不平衡 Class Imbalance”)的技术。
ai举的例子我觉得很透彻:
想象你正在教一个 AI 模型识别图片:
你给了它 900 张猫的图片(多数类,Majority Class)。
你只给了它 100 张狗的图片(少数类,Minority Class)。
后果:
这个模型会变得很“懒”且“滑头”。它只要闭着眼睛全部猜“是猫”,准确率就能达到 90%!它根本不需要去学狗长什么样。
这就导致模型在预测“狗”的时候效果极差(Recall 很低)。
Up-sampling 的解决办法:
为了不让模型偷懒,你把那 100 张狗的图片,复制粘贴(或者通过算法生成类似的)多份,直到凑够 900 张。
现在,猫 900 张,狗 900 张。模型如果再瞎猜,准确率就只有 50% 了。这就逼着模型必须认真去学“狗到底长什么样”。
本文同理,因为数据集中“不好”的数据比较少,所以把它们等比例复制到和“好”的数据差不多同样多。
启发
感觉也是可以指引的方向:
- 自动生成任务的评价指标: 现有的 Automated Code Review Generation 还在用 BLEU 指标(上一篇论文也有提到,感觉可以联动一下)。但这篇论文告诉我们要追求 Quality 而不是 Similarity。高 BLEU 分数不代表评论写得清晰。
- 数据清洗: 以后做生成模型训练时,Garbage In, Garbage Out。可以利用 ClearCRC 或者 RIE 标准,先把训练集里的“坏数据”(模糊的、不礼貌的、无信息量的评论)过滤掉,这样训练出来的模型效果肯定更好。
- Prompt Engineering 参考(这个是真干货,已悄悄收藏):
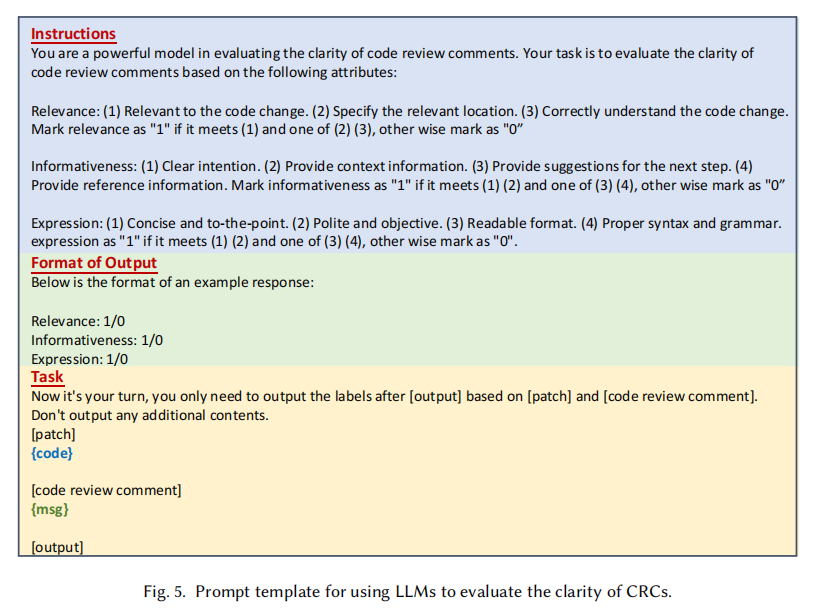
依旧是个人碎碎念:
这也提醒了我们自己写 Code Review 的时候,一定要由着重注意 “Reasoning”和 “Politeness”!!
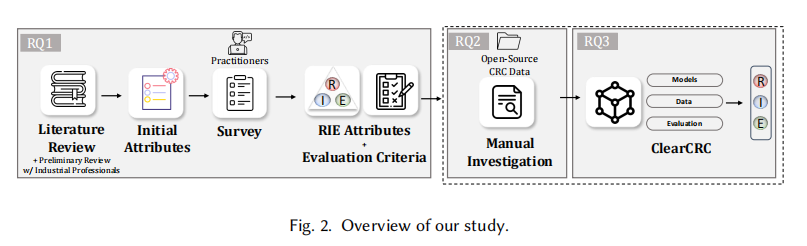
图片不仅可以用来展示数据啊结果啊,也可以用来展示工作过程,如下图。感觉论文构思的时候可以借鉴这种 structure。
0 条评论