论文地址: https://arxiv.org/pdf/2509.21009。
依旧记录一些自己学到的东西。
标准的RL后训练三阶段:
rollout(模型生成响应);
reward(评估响应);
training(更新模型权重)。
文章指出 rollout阶段耗时最长(约70%),且响应长度的长尾分布导致了严重的GPU闲置。
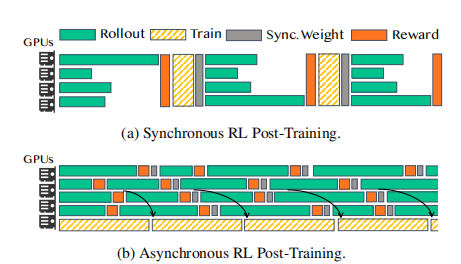
补充:
long-tail responses:长尾分布,就是指响应长度不均衡导致GPU利用率低下,产生所谓的“bubbles”。
GPU Bubbles:顾名思义就是GPU闲置产生的气泡(感觉计原里也有这种差不多说法)。
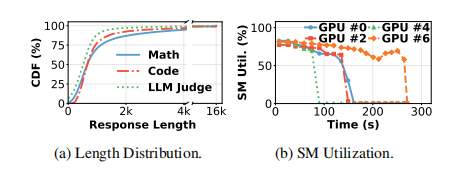
解决长尾分布的已有方法:
- Stage Overlap,阶段重叠,效果有限,因为reward和reference模型推理的计算量不足以完全掩盖rollout的空闲时间;
- Relaxed Synchronization,放宽同步约束,虽然能减少空闲,但会引入“陈旧”的模型权重,损害训练的准确性和稳定性。
所以有了本文的标题 —— RollPacker 方法。
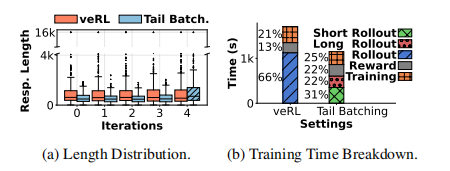
tail batching尾部批处理 —— RollPacker 算法的核心策略
speculative execution 推测执行
在短轮次中,系统会启动比所需数量更多的 prompt 和 response 生成任务。它只保留最先完成的指定数量的提示和响应,从而主动“过滤掉”那些生成速度慢(通常是长响应)的任务。
long-prompt queue 长提示队列
被推测执行“抛弃”的慢任务并不会被丢弃,而是被放入一个专门的队列。当这个队列中的提示积累到一定数量时,系统会启动一个“长轮次”,在这个轮次中关闭推测执行,让这些长响应能够完整生成。
这两种方法只是重新排序了训练样本,并不会改变样本的整体分布,因此不会损害模型精度(见下图)。
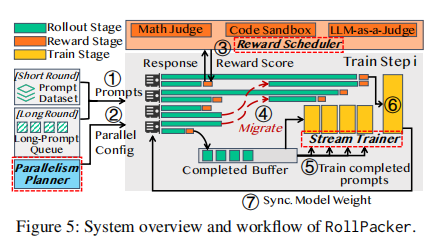
在提出了tail batching思想后,本章描述了如何围绕这个思想构建一个高效的系统——RollPacker。
论文指出,当rollout效率提升后,reward和training阶段可能成为新的瓶颈。因此,RollPacker包含了三个协同工作的关键组件:
- Parallelism Planner 并行策略规划器:动态调整 Tensor Parallelism(并行张量) 的大小。因为短轮次和长轮次的内存压力不同,固定的TP配置不是最优的。该规划器能根据当前是短轮次还是长轮次以及内存使用情况,自动选择最佳的TP配置。
- Reward Scheduler 奖励计算调度器:将奖励计算与rollout过程流水线化,并为不同类型的奖励任务动态调整计算资源和超时策略,以减少奖励计算的延迟。
- Stream Trainer 流式训练器:在长轮次中,当一部分GPU提前完成其rollout任务变为空闲时,这个训练器会立即将这些空闲GPU重新分配用于训练,并将已完成的样本流式地送入训练阶段,从而实现rollout和training阶段在同一个批次内的细粒度重叠。
全流程如下图(这个图也画的好厉害,麻雀虽小五脏俱全):
结尾碎碎念:
实验的测试在上一篇论文的一层层测试的基础上,多了一个,对单个部件的测试,感觉更全面了。另外也做了参数敏感度的测试。
本篇论文的图真的很厉害,把原来那些配色和元素玩出花了。
0 条评论