论文地址:arXiv:2509.13650
论文总结一句话:Copilot的自动 CR 无比之烂。
发现
作者在论文开头指出,大家可能认为 Copilot 能帮我们找出代码里的 Bug,但事实是,各种意义上都完全不行。(但u1s1,这也说明有前景嘛……(也许))
- 在 7 个包含数百个已知漏洞的基准数据集中,Copilot 总共只生成了不到 20 条评论。检测率极低
- 另外,它几乎完全忽略了高危漏洞,反而热衷于纠正 拼写错误(Typos) 和 代码风格 问题。关注点跑偏了。
- 目前的 Copilot Code Review 完全不具备安全意识,无法替代 CodeQL 或人工审计。
实验设计
作者选取了多个著名的代码库。
- 数据集:WebGoat、Wireshark(真实软件漏洞)、Android 应用等。
- 把明知有漏洞的代码提交 PR,触发 Copilot 自动审查,看它说什么。
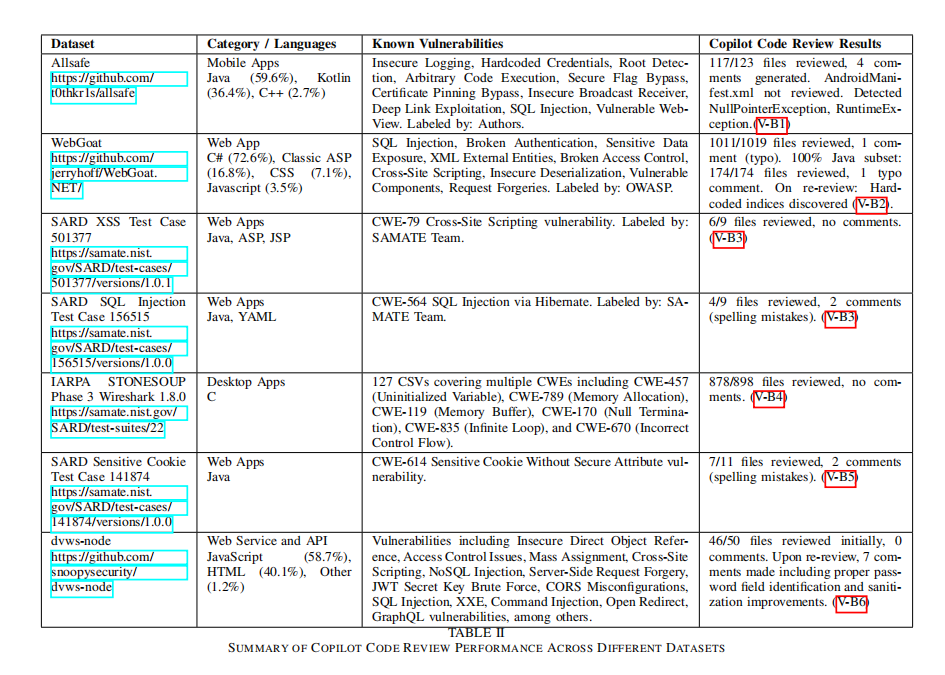
结果惨不忍睹(参考 Table II):
- AllSafe (移动端):审查了 117 个文件,只给了 4 条无关痛痒的建议。完全无视了
AndroidManifest.xml里的配置错误。 - WebGoat (Web):满是 SQL 注入和 XSS ,Copilot 居然只指出了一个拼写错误。
- Wireshark (C语言):审查了 878 个文件(包含缓冲区溢出等严重漏洞),结果是 0 条评论。
一些有意思的具体案例
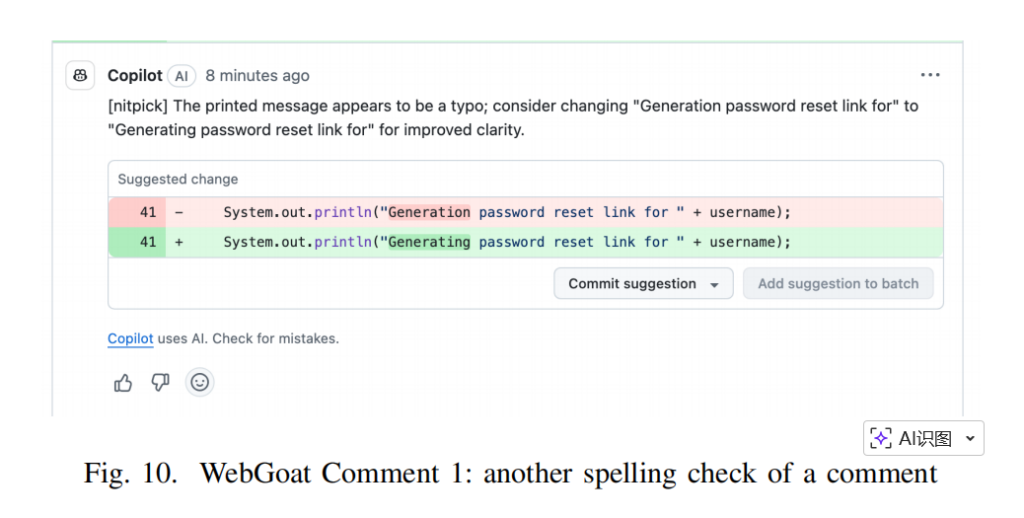
案例一:WebGoat
代码里明明写着明晃晃的 SQL 注入漏洞,Copilot 的评论却是:
“[nitpick] The printed message appears to be a typo… ‘Gennerating’ -> ‘Generating'”
([挑刺] 打印的信息里有个错别字,把 Gennerating 改成 Generating 吧。)
“它完美地避开了旁边的安全大坑,专心致志地改错别字”(感觉作者都无奈了)。
案例二:盲区 (Blind Spots)
Copilot 似乎完全不读配置文件。在安卓项目中,权限配置都在 AndroidManifest.xml 里,但 Copilot 直接跳过了这个文件。
原因分析
作者总结了 Copilot Code Review 失效的几个主要原因:
- 浅层理解 (Shallow Context):它似乎只能理解当前的局部代码,无法理解跨文件、跨函数的数据流。比如,它不知道用户输入的数据在三层函数调用后进入了数据库查询。
- 非确定性 (Non-deterministic):同一段代码,提交两次,Copilot 给出的反应可能完全不同。这种随机性在安全领域是不可接受的。
- 文件类型限制:对于 XML, YAML 等配置文件支持极差。
结尾碎碎念
- 千万别信 Copilot 的 PR 审查结果来做安全背书。
- 有趣的是,论文提到 Copilot Chat (Ask Copilot) 的表现其实比自动 Code Review 要好。如果你主动问它“这段代码有安全漏洞吗?”,它往往能答对。这说明模型本身是有能力的,但“自动审查”这个产品的工程化(Prompt设计、上下文提取)可能还做得太烂。
0 条评论